
Background Matting 发布2.0 版本 实时视频抠图再升级毛发细节到位
实时运行、使用单块英伟达 RTX 2080 TI GPU 即可以实现 HD 60fps 和 4K 30fps 的速度,那个「让整个世界都变成你的绿幕」的抠图方法 Background Matting 发布了 2.0 版本,为用户提供了更自然更快速的实时背景替换效果。
背景替换是电影特效中的关键一环,在 Zoom、Google Meet 和 Microsoft Teams 等视频会议工具中得到广泛应用。除了增加娱乐效果之外,背景替换可以增强隐私保护,特别是用户不愿在视频会议中向他人分享自身位置以及环境等细节时。而这面临着一项关键挑战:视频会议工具的用户通常无法获得电影特效背景替换所使用的绿幕或其他物理条件。
为了使用户更方便地替换背景,研究人员陆续开发了一系列抠图方法。今年 4 月份,华盛顿大学研究者提出了 background matting 方法,不在绿幕前拍摄也能完美转换视频背景,让整个世界都变成你的绿幕。但是,这项研究无法实现实时运行,只能以低帧率处理低分辨率下(512×512)的背景替换,有很多需要改进的地方。
八个月过去,这些研究者推出了 background matting 2.0 版本,并表示这是一种完全自动化、实时运行的高分辨率抠图方法,分别以 30fps 的帧率在 4k(3840×2160)和 60fps 的帧率在 HD(1920×1080)图像上实现 SOTA 结果。
先来看一些效果展示场景:
这位小哥将自己乱糟糟的房间背景替换成了下雪场景。
Background Matting 2.0 相较 1.0 版本有哪些技术改进呢?我们都知道,设计一个对高分辨率人物视频进行实时抠图的神经网络极具挑战性,特别是头发等细粒度细节特别重要的情况。1.0 版本只能以 8fps 的帧率实现 512×512 分辨率下的背景替换。若要在 4K 和 HD 这样的大分辨率图像上训练深度网络,则运行会非常慢,需要的内存也很大。此外,它还需要大量具备高质量前景蒙版(alpha matte)的图像以实现泛化,然而公开可用的数据集也很有限。
收集具有大量手动制作前景蒙版的高质量数据集难度很大,因此该研究想要通过一系列具有不同特性的数据集来训练网络。为此,他们创建了两个数据集 VideoMatte240K 和 PhotoMatte13K/85,二者均包含高分辨率前景蒙版以及利用色度键软件提取的前景层。研究者首先在这些包含显著多样化人体姿势的较大型前景蒙版数据集上训练网络以学习鲁棒性先验,然后在手动制作的公开可用数据集上继续训练以学习细粒度细节。
此外,为了设计出能够实时处理高分辨率图像的网络,研究者观察发现图像中需要细粒度细化的区域相对很少。所以他们提出了一个 base 网络,用来预测低分辨率下的前景蒙版和前景层,并得到误差预测图(以确定哪些图像区域需要高分辨率细化)。然后 refinement 网络以低分辨率结果和原始图像作为输入,在选定区域生成高分辨率输出。
结果表明,Background Matting 2.0 版本在具有挑战性的真实视频和人物图像场景中取得了 SOTA 的实时背景抠图结果。研究者还将公布 VideoMatte240K 和 PhotoMatte85 数据集以及模型实现代码。
论文地址:https://arxiv.org/pdf/2012.07810.pdf 项目主页:https://grail.cs.washington.edu/projects/background-matting-v2/ 数据集
该研究使用了多个数据集,包括研究人员创建的新型数据集和公共数据集。
公共数据集
Adobe Image Matting(AIM)数据集提供了 269 个人类训练样本和 11 个测试样本,平均分辨率约为 1000×1000。该研究还使用了 Distinctions646 数据集的 humans-only 子集,包含 362 个训练样本和 11 个测试样本,平均分辨率约为 1700×2000。这些数据集中蒙版均为手动创建,因此质量较高。但训练样本数量较少,无法学习多样化的人类姿势和高分辨率图像的精细细节,于是研究人员创建了两个新的数据集。
新型数据集 VideoMatte240K 和 PhotoMatte13K/85
VideoMatte240K 数据集:研究者收集了 484 个高分辨率绿幕视频(其中 384 个视频为 4K 分辨率,100 个 HD 分辨率),并使用色度键工具 Adobe After Effects 生成 240709 个不同的前景蒙版和前景帧。
PhotoMatte13K/85 数据集:研究人员收集了 13665 张图像,这些图像是用演播室质量的照明和相机在绿幕前拍摄的,并通过带有手动调整和误差修复的色度键算法提取蒙版。
下图展示了这两个数据集中的样本示例:
给定图像 I 和捕获背景 B,该研究提出的方法能够预测前景蒙版 α 和前景 F。
具体而言,该方法通过 I'= αF + (1−α)B' 基于新背景进行合成(B' 为新背景)。该方法没有直接求解前景,而是求解前景残差 F^R = F − I。然后通过向输入图像 I 添加 F^R 来恢复 F:F = max(min(F^R + I, 1), 0)。研究人员发现该公式可以改善学习效果,并允许通过上采样将低分辨率前景残差应用到高分辨率输入图像上。
使用深层网络会直接导致大量计算和内存消耗,因此高分辨率图像抠图极具挑战性。如图 4 所示,人类蒙版通常非常稀疏,其中大块像素区域属于背景(α=0)或前景(α=1),只有少数区域包含较精细的细节(如头发、眼镜、人体轮廓)。因此该研究没有设计在高分辨率图像上直接运行的网络,而是提出了两个网络:一个基于较低分辨率图像运行,另一个基于先前网络的误差预测图选择图像块(patch),仅在这些图像块上以原始分辨率运行。
该架构包含 base 网络 G_base 和 refinement 网络 G_refine。
给出原始图像 I 和捕捉背景图 B,该方法首先使用因子 c 对图像 I 和 B 执行下采样,得到 I_c 和 B_c。然后 base 网络 G_base 以 I_c 和 B_c 为输入,预测粗粒度前景蒙版 α_c、前景残差 F^R_c、误差预测图 E_c 和隐藏特征 H_c。紧接着 refinement 网络 G_refine 使用 H_c、I 和 B 在预测误差 E_c 较大的区域中细化 α_c 和 F^R_c,得到原始分辨率的蒙版 α 和前景残差 F^R。
该模型为全卷积模型,可以处理任意大小和长宽比的图像。
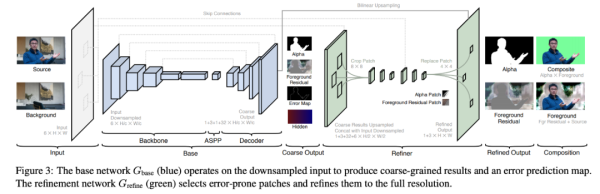
架构图。
base 网络
该方法的 base 网络是一个受 DeepLabV3 和 DeepLabV3+ 启发的全卷积编码器 - 解码器网络,包含三个主要模块:骨干网络、ASPP 和解码器。
研究者采用 ResNet-50 作为编码器骨干网络,它可以被替换为 ResNet-101 和 MobileNetV2 以实现速度和质量之间的权衡。
和 DeepLabV3 方法一样,该方法在骨干网络之后采用了 ASPP(空洞空间金字塔池化)模块,该模块包含多个空洞卷积滤波器,扩张率分别为为 3、6、9。
解码器网络在每一步均使用了双线性上采样,结合来自骨干网络的残差连接(skip connection),并使用 3×3 卷积、批归一化和 ReLU 激活函数(最后一层除外)。解码器网络输出粗粒度的前景蒙版 α_c、前景残差 F^R_c、误差预测图 E_c 和 32 通道的隐藏特征 H_c。H_c 包含的全局语境将用于 refinement 网络中。
refinement 网络
refinement 网络的目标是减少冗余计算并恢复高分辨率的抠图细节。base 网络在整个图像上运行,而 refinement 网络仅在基于误差预测图 E_c 选择的图像块上运行。refinement 网络包括两个阶段:先以原始分辨率的 1/2 进行细化,再用全分辨率细化。在推断过程中,该方法细化 k 个图像块,k 可以提前设置,也可以基于权衡图像质量和计算时间的阈值进行设置。
实验
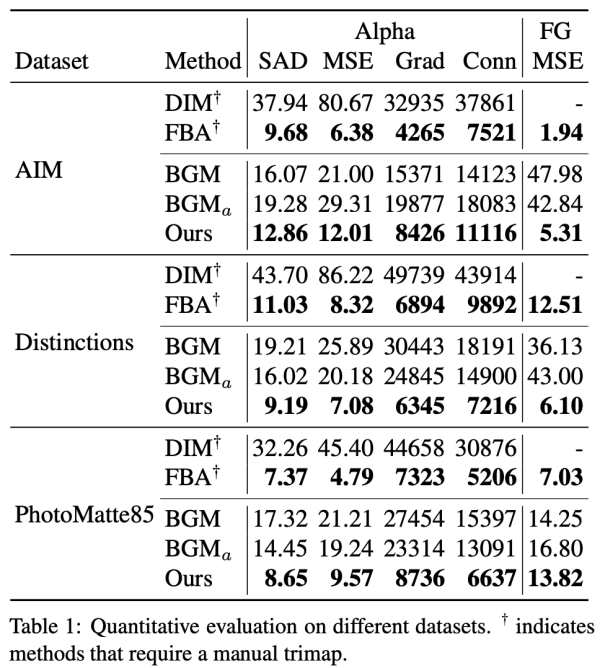
该研究将这一方法与基于 trimap 的两种方法 Deep Image Matting、FBA Matting (FBA) 和基于背景图像的方法 Background Matting (BGM) 进行对比。
在合成数据集上的评估结果
下表 1 展示了这些方法在不同数据集上的量化评估结果。从中可以看出,该研究提出的方法在所有数据集上均优于基于背景的 BGM 方法,但略逊于当前最优的 trimap 方法 FBA,FBA 需要人工精心标注的 trimap 且速度比该研究提出的方法慢。
在现实数据上的评估结果
该研究还对比了这些方法在真实数据上的性能。从下图中可以看出,该研究方法的生成结果在头发和边缘方面更加清晰和详细。
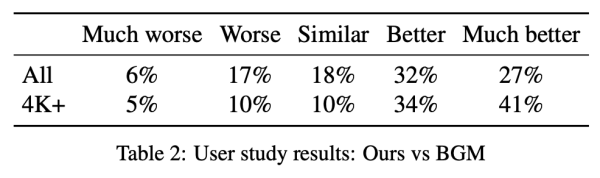
该研究邀请 40 位参与者评估该方法与 BGM 的生成效果,结果参见下表 2。从中可以看出该方法较 BGM 有显著提升。59% 的参与者认为该算法更好,而认为 BGM 更好的参与者比例仅为 23%。在 4K 及更高分辨率的样本中,认为该方法更好的参与者比例更是高达 75%。
性能对比
下表 3 和表 4 表明该方法比 BGM 小但速度更快。
该方法的参数量仅为 BGM 的 55.7% 。但它在批大小为 1 的情况下,使用一块英伟达 RTX 2080 TI GPU就能够实现 HD 60fps 和 4K 30fps 的速度,可用于很多实时应用。相比之下,BGM 只能以 7.8fps 的速度处理 512×512 分辨率图像。
将该方法的骨干网络换成 MobileNetV2 后,其性能得到了进一步提升,实现了 HD 100fps 和 4K 45fps。

实际使用
研究人员将此方法应用到了Zoom 视频会议和抠图这两种场景中。
在 Zoom 实现中,研究人员构建了拦截摄像头输入的 Zoom 插件,收集一张无人的背景图,然后执行实时视频抠图和合成,在 Zoom 会议中展示结果。研究人员使用 720p 摄像头在 Linux 中进行了测试,实际效果很好。
此外,研究人员对比了该方法和绿幕色度抠图的效果,发现在光照不均匀的环境下,该方法的效果胜过专为绿幕设计的方法,
相关阅读
-
华为Mate 60系列或将首发卫星电话功能...
近日,一名数码博主确认了华为Mate60系列将首发卫星电话功能的消息,引 -
星纪魅族回应优化应届生:内部优先分流
据车媒报道,近日,网传星纪魅族AR芯片业务部门因业务无实际产出且投资 -
在旅途重新定义评测 PConline推全新栏...
【太平洋科技资讯】2022年07月26日,PConline太平洋科技正式推出旗下全 -
让智造看得见, PConline推出全新栏目...
PConline正式推出旗下全新栏目“中国智造的力量”。“中国智造的力... -
全面拥抱智能化 朱志延出任太平洋汽车...
6月7日中午,太平洋汽车发布了新的人事任命。太平洋网络集团任命朱志延 -
百度肖阳:奇点降临,搜索迎来代际变革
5月25日,2023万象·百度移动生态大会在广州召开。会上,百度集团资...
精彩推送
-
2024 年助力品牌全域经营 SaaS 工具
海量智能是一家专注于智能营销工具研发和用户运营解决方案的创新型 -
实现全流程国产化 蜜巢政务大模型3.0重...
2024年7月4日,2024世界人工智能大会暨人工智能全球治理高级别会议 -
加速“人工智能+”总台研究院主办活动来啦
“人工智能必须是发展与治理同步,政府要划定边界,特别要在国际上加 -
国科微全系边端AI芯片闪耀WAIC2024:加...
7月4日,2024世界人工智能大会(以下简称“WAIC2024”)在上海开幕 -
钛虎科技机器人震撼发布:T170A“瑶光”...
2024年7月4日 —— 在全球瞩目的2024世界人工智能大会(WAIC)暨人... -
拐点已在眼前,北汽蓝谷积聚向上势能
伴随着中国新能源汽车市场的高速发展,各家新能源汽车企业的表现都备 -
年轻员工猝死频发:沃民高科AI引擎驱动...
在科技快速发展的今天,高强度的工作节奏已成为许多行业尤其是科技 -
强者恒存!曙光存储重磅新品再破存力上限
6月25日,曙光存储召开了主题为“先进存力,凝聚数据要素”的新品暨... -
国产“Omniverse”诞生! 联想新视界重...
近年来,以英伟达Omniverse为代表的元宇宙平台在元宇宙国际竞争中呈 -
丝芭传媒旗下美踏元宇宙和鹦鹉人启动内...
6月26日,丝芭传媒旗下酝酿已久的创新AIGPT及AIGC生成工具APP“鹦鹉 -
李德毅院士:人类的四种基本认知模式
编者按人类认知的整个活动,就是如何解释、解决人类在生存和繁衍过 -
视觉生成式AI如何引领各行各业创新?CVP...
导语:50+ 论文成果、CVPR 自动驾驶大挑战赛“端到端规模驾驶“获 -
AI下半场 宁畅智算中心以全栈全液助推...
当前,人工智能以前所未有的速度塑造各行各业,全国范围内对智算中 -
身怀全栈全液能力 宁畅打造智算中心部...
当前,人工智能以前所未有的速度塑造各行各业,全国范围内对智算中 -
淘宝直播“勇往直前的CEO”再添一员,AI...
自淘宝推出勇往直前的CEO计划以来,一大拨企业家正涌向淘宝直播间。6... -
存算“全能王”!中科可控重磅发布新一...
当前,人工智能应用快速落地、多模态大模型加速迭代,亿万数据让计 -
高能来袭|联想拯救者携手《黑神话:悟空...
从2020年首次发布实机演示视频以来,《黑神话:悟空》便在全球范围 -
YYDS!联发科携最新AI创新应用亮相COMPUTEX
近日,备受全球瞩目的COMPUTEX 2024科技展会在热烈的氛围中拉开帷 -
广西村支书用AI制作视频带货,网友:接...
近日,一则广西勒水村的新闻屡见报端,当地村民用AI做短视频带货,推广 -
COMPUTEX 2024开展:联发科大秀全景AI...
在最近开幕的COMPUTEX 2024科技展会上,联发科展示了其最新的AI技 -
“AI+全场景”!中科可控AI工作站来袭
近年来人工智能技术极速发展,“AI+”已然成为行业用户对于体验升级... -
阿丘科技:生成式AI与行业视觉大模型驱...
5月21日,阿丘科技CEO黄耀应邀参加北京机器视觉助力智能制造创新发展 -
AI赋能 智赢百业 中国移动成功举办AI+...
5月25日,在第七届数字中国建设峰会期间,中国移动举办了以“AI赋能 -
直击2024年数字中国峰会中国移动AI+行业...
5月25日,数字中国峰会中国移动AI+行业分论坛在福建福州盛大召开, -
5月23日-27日@数字中国建设峰会,每日互...
一年一度,相约福州。5月23日至27日,第七届数字中国建设峰会系列活 -
天工AI搜索解读《如懿传》的“招黑体质”
《如懿传》又“火”了。同为“宫斗”题材的清宫戏,相比于至今仍在... -
AVK119简介:SCI 最新的变频涡旋压缩机
AVK119采用三菱电机专利的最新椭圆形涡旋技术设计,与相同尺寸的压 -
普惠AI破局视觉智能化 中小企业迎来发...
在数字化转型浪潮席卷全球之际,视觉智能化作为AI技术的重要分支,正 -
官宣!仰韶彩陶坊酒连续十一年荣膺“黄...
三月三,拜轩辕。在中国传统文化的传承中,这一敬拜黄帝先祖的节日 -
全国人大代表、中国移动辽宁公司总经理...
“数字乡村建设有助于促进农业全面升级、农村全面进步、农民全面发 -
热辣滚烫 盈出精彩|LG gram Pro AI...
LG gram于今年1月份上市了首款AI超轻薄本。它延续了轻薄长续航的基 -
从这部微电影开始,传承一杯“家乡味”
年中,一曲土中带潮的《恐龙抗狼》,火爆全网;年终,一支笑中带泪 -
生成式AI就绪 英特尔发布第五代至强可...
实用化 AI 算力又升上了一个新台阶。随着AI大模型加速迭代,智能 -
泰瑞应急数字孪生底座赋能防灾减灾,提...
近年来,灾害频发,给人们的生命和财产安全带来了巨大威胁。为提升 -
借助AI 数字人,光谷电商科技为什么成...
随着AI技术的蓬勃发展,数字化时代的大幕正式拉开。在这个时代,电 -
性价比提升超30%,腾讯云发布新一代基于...
基础设施的硬实力,愈发成为云厂商的核心竞争力。11月24日,腾讯云 -
山东原创《丝路》动画片央视首播
由枣庄市一甲动漫制作股份有限公司打造的大型原创52集《丝路》动画 -
2023深圳高交会今日开展,AI创新先睹为快!
2023深圳高交会今日盛大开幕,数据显示有超过100个国家和地区组团, -
2023深圳高交会IT展盛况:AI技术成焦点...
11月15日-19日,中国国际高新技术成果交易会(简称:高交会)在深圳 -
2023第二届长三角国际汽车产业及供应链...
2023第二届长三角国际汽车产业及供应链博览会将于2023年10月26-28日 -
“全球精品家轿”2024款艾瑞泽5焕芯上市...
畅销全球80多个国家和地区、斩获全球100万用户的艾瑞泽5,再次焕新 -
Colossal-AI助力智能化升级新时代
在这个快速发展的数字化时代,人工智能(AI)作为推动社会进步的核 -
当远铁路跨焦柳线特大桥成功转体
10月11日凌晨,湖北铁路集团当远铁路跨焦柳线特大桥转体成功,为当 -
微盟集团同时入选恒生人工智能、传媒指...
9月25日,恒生指数公司推出恒生人工智能主题指数和恒生传媒指数,微 -
锐进 求新 创无限 | 品达集团产品战...
2023年9月20日,“锐进、求新、创无限” 品达集团产品战略发布会暨 -
生态出海高歌猛进,海外月销3万辆,日系...
如今,中国汽车迎来了百年一遇的窗口期,同时汽车市场也进入了白热 -
孙树峰院士:激光技术的革命,开启未来...
9月1日,在智能制造助力高质量发展高峰论坛上,俄罗斯自然科学院外籍院 -
国产车赢麻了!中国品牌车企占泰国电动...
国产车赢麻了!中国品牌车企占泰国电动车市场8成份额 -
2023新思科技开发者大会:以创新引领航...
中国上海–9月8日,芯片行业年度嘉年华“2023新思科技开发者大会”... -
基于Android™ 14 Beta的 ColorOS 1...
9月11日,OPPO开启了基于Android™14Beta的ColorOS14全球公测尝鲜,首 -
公司回应禁止管理层买、开理想汽车:情...
公司回应禁止管理层买、开理想汽车:情况属实、律师 理想官方表态 -
上市告吹后 开心汽车宣布并购威马
上市告吹后开心汽车宣布并购威马 -
格局打开!小米汽车获SIG认证:支持苹果...
格局打开!小米汽车获SIG认证:支持苹果CarPlay -
TrendForce集邦咨询: NAND Flash第四...
Sep 11,2023----近日,三星(Samsung)为应对需求持续减弱,宣布9月起扩 -
真“自动挡”来了!特斯拉新款Model 3...
真“自动挡”来了!特斯拉新款Model3可自动选择前进后退 -
“人工智能+”,点燃智能制造发展新引擎...
近日,21ic有幸采访了辽宁省人工智能学会理事长李鸿儒教授,围绕“... -
全国唯一综合性种植资源库 四川省种质...
9月9日,第二届天府国际种业博览会暨四川省种质资源中心库揭牌仪式在成 -
问界M9率先用上!华为AR-HUD有多强:75...
问界M9率先用上!华为AR-HUD有多强:75寸画幅彻底干掉仪表盘 -
一万买到多少续航?新势力又出奇怪榜单...
一万买到多少续航?新势力又出奇怪榜单:特斯拉倒数第一 -
无锡相关部门回复网友反映某学校使用过...
2023年9月8日14时50分,有网友反映无锡市梁溪区连元街小学午餐使用了过 -
礼让救护车、搬抬婴儿车……青岛街头,...
救护车呼啸而至,驾驶员快速打方向盘让出生命“通道”;乘客推婴儿... -
我要打十个!消息称华为ADS 2.0年底开...
我要打十个!消息称华为ADS2 0年底开城数量调整:覆盖全国 -
坚守三尺讲台 潜心教书育人(教育时评)
金秋九月,1800多万名人民教师迎来属于自己的节日——第三十九个教... -
联想S205CPU更换(联想s205)
来为大家解答以上问题,联想S205CPU更换,联想s205很多人还不知道,现 -
获近40亿补贴!中国电池制造商国轩高科1...
获近40亿补贴!中国电池制造商国轩高科147亿在美建厂计划敲定 -
2023年9月9日云南省南瓜批发价格行情
2023年9月9日云南省南瓜批发市场价格最新行情监测显示:2023年9月9日云 -
西甲官方:马竞vs塞维利亚将在12月23日补赛
西甲官方宣布,此前由于暴雨延期的第四轮马竞vs塞维利亚的比赛,将会推 -
国家统计局:8月份居民消费价格同比上涨...
证券时报网讯,据国家统计局,2023年8月份,全国居民消费价格同比上涨0 -
10天内至少24城“认房不认贷”,效果如...
从“认房又认贷”到“认房不认贷”,一字之别的背后,是13年来我国... -
哈尔滨多车加油后开出不远就熄火 加油...
哈尔滨多车加油后开出不远就熄火加油站:进水了、已赔付 -
坚守三尺讲台 潜心教书育人(教育时评)
金秋九月,1800多万名人民教师迎来属于自己的节日——第三十九个教... -
长江通信:9月8日融资买入553.36万元,...
9月8日,长江通信(600345)融资买入553 36万元,融资偿还567 15万元, -
八音之韵丨来听听大音希声的太古之音
于高山流水之间 聆听声律之美 于明月松林之中 感受万物空明 这是人 -
华为加持的阿维塔新车 敢要价40万?
华为加持的阿维塔新车敢要价40万? -
抽奖券怎么写(抽奖卷模板)
今天之间网超哥来为大家解答以上的问题。抽奖券怎么写,抽奖卷模板相信 -
2035年停售燃油车不现实 世界第四大汽...
2035年停售燃油车不现实世界第四大汽车集团:我要卖到2050年 -
中国首款自研车规级7纳米芯片 “龙鹰一...
中国首款自研车规级7纳米芯片“龙鹰一号”性能如何?稍差于骁龙8155 -
行业首个!Flyme Auto获得泰尔“卓越级...
行业首个!FlymeAuto获得泰尔“卓越级”认证魅族:遥遥领先 -
领克08正式上市:92英寸无界AR-HUD 20.88万起
领克08正式上市:92英寸无界AR-HUD20 88万起 -
车评头条:中期提速能力意外 海马M3 1...
汽车已经成为人们生活的必须品了,很多车的适不适合自己很生疏,现在汽 -
近况曝光!72岁知名老戏骨街头被偶遇,...
所以如今有网友在社交平台上晒出偶遇到郑则仕,并且对方还如此精神,就 -
dnf二次觉醒任务(二次觉醒任务流程)
很多人对dnf二次觉醒任务,二次觉醒任务流程不是很了解那具体是什么情 -
暑假出游景点(暑假出游好去处)
诸多的对于暑假出游景点,暑假出游好去处这个问题都颇为感兴趣的,为大 -
兆邦基地产(01660.HK):张彧获委任为执...
格隆汇9月8日丨兆邦基地产(01660 HK)公告,董事会宣布:(i)许志聪已获 -
广汇能源遭遇外资抛售49.6万股|外资买卖
外资卖出:广汇能源(600256)(600256)于2023年9月7日遭遇外资抛售,数 -
白露至 各地一片农忙景象
白露节气已至,各地农民抢抓农时,田间地头一片农忙景象。在湖北省襄阳 -
张艺谋遗憾《坚如磐石》迟到:于和伟的...
极目新闻记者戎钰国庆档看什么?由张艺谋执导的都市罪案题材电影《坚如 -
警察叔叔发布“挑战令”全市7248人挑战成功
9月8日,第三届“百日零违法文明交通好榜样”颁奖仪式在清城区举行... -
或将采用“国风”设计:哪吒X内饰公布 ...
或将采用“国风”设计:哪吒X内饰公布专为年轻人打造 -
三种配色 7座布局 广汽合创MPV V09内...
三种配色7座布局广汽合创MPVV09内饰曝光10月13日上市首发 -
担保期过不过怎么办
担保期是否已经届满,需要根据具体情况分析。1、如果在担保合同中约定 -
中国正在开展HCFCs加速淘汰行动
中新社北京9月8日电(记者阮煜琳)中国生态环境部大气环境司有关负责人8 -
大众再放大招:ID.6 CROZZ 限时官降4....
大众再放大招:ID 6CROZZ限时官降4 5万售价25 89万起 -
138度超广角!70迈3K夜视流媒体后视镜将...
138度超广角!70迈3K夜视流媒体后视镜将开售:一次能看三车道 -
乘联会:8月乘用车市场零售192万辆,同...
乘联会:8月乘用车市场零售192万辆,同比增长2 5%,零售,乘联会,乘用车市场 -
载歌载舞打一个生肖 载歌载舞打一个生...
小枫来为解答以上问题。载歌载舞打一个生肖,载歌载舞打一个生肖具体是 -
交付1.2万成合资黑马!别克E5迎首次OTA...
交付1 2万成合资黑马!别克E5迎首次OTA:上电逻辑不再反人类 -
阿塞拜疆vs比利时比赛预测 阿塞拜疆vs...
阿塞拜疆vs比利时比赛预测,风暴体育讯北京时间9月9日21:00,新赛季欧 -
工行首席技术官:银行业财富管理面临挑...
工行首席技术官:银行业财富管理面临挑战,数字化转型是大势所趋,工行, -
“原子弹之父”奥本海默开什么车?凯迪...
“原子弹之父”奥本海默开什么车?凯迪拉克认领:1941款敞篷经典







